Toxicity in online forums
Something I’ve found particularly interesting recently is how communities on the social networking site, Reddit, can be quarantined. Being quarantined on reddit indicates that the contents of a forum (or ‘subreddit'), while not breaking site rules on content, can nevertheless be highly offensive and upsetting or promote hoaxes. These communities then are placed under ‘quarantine,’ meaning that Reddit users must explicitly opt-in to view this content, instead of the traditional opt-out process of the social media site.
Knowing this, I had to ask: can we use sentiment analysis to see the differences in language across the quarantine line?
The Data
What is also amazing about Reddit is the accessibility of data on this platform—actually, so much data that my computer couldn’t handle holding and analyzing it! Reddit users regularly use the Reddit API to query data on posts. Once pulling that data from the API, they store it on Google’s Big Query platform (as well as storing it for academic torrenting). Due to the sheer volume of posts on Reddit, I examined 100,000 posts randomly taken from October 2018. I queried this from Google Big Query, rather than scraping myself, as there was a higher likelihood of finding deleted posts before their content had been removed from Reddit’s live site.
This took a simple SQL query. Amazingly, Reddit not only provides data on where posts were posted, but also provides a binary variable on whether the post was quarantined. I simply pulled the post’s title and it’s quarantine status, and let the little version of this large dataset live on my computer.
There are some variables that would be unaccounted for in this—for example, if there were major news that were communicated, or whether there was an image posted, so the title doesn’t provide as much clarity (sometimes, users may post an image with the title “An interesting title” when they are unable to come up with a good title for the image). I don’t think that particular communities have greater or less title creativity overall. Additionally, I am assuming that images are posted at similar rates between communities that have been quarantined and communities that have not.
Cleaning & tidytext
Once the data was pulled, I had to do some cleaning. When doing sentiment analysis, it’s important to get rid of any neutral words, since the dataset increases substantially when it is broken down to one word per observation. To do this, I did the typical cleaning — e.g., “we’re” to “we are”— but there was also some atypical cleaning I had to do. By pulling largely from a website steeped in internet slang, I also had to clean some frequently used internet language on the platform. You can see what I cleaned here in the function on the right.
There’s a lot of slang that I obviously couldn’t cover. I tried to go for the most common slang I see on the platform, particularly in title posts. Suggestions welcome on how to do this in a smarter way.
Once everything was cleaned, I was able to use R’s tidytext package to begin my sentiment analysis. The tidytext package provides several different lingual sentiment dictionaries. Some, for example, provide a numeric grading scale from positivity to negativity, while others place the words into unique sentiment groups.
tidytext is especially helpful, because on top of providing dictionaries, it also provides mechanics to remove filler words (e.g. “as,” “they,” “were”). So I first removed these words from the posts before moving on to my analysis.
Writing curse words in my code was a first.
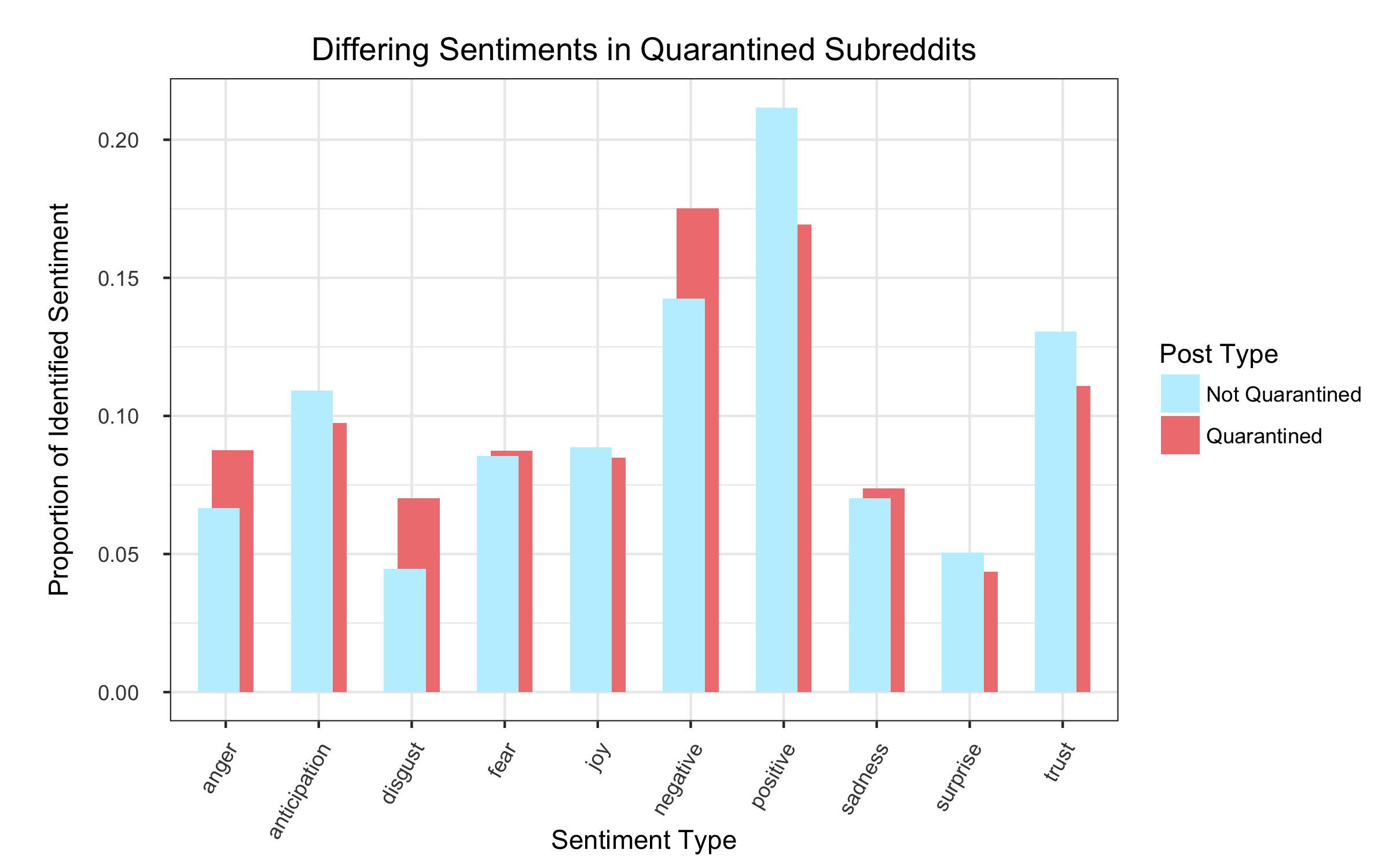
Sentiments are actually significantly different between these communities.
The Analysis
The first thing to know is that quarantined posts made up roughly 3% of my sample size. Given that Reddit saw nearly 14 million posts in October 2018, this is actually nothing to sneeze at. These quarantined communities are active on a daily basis, regardless of whether they’re quarantined or not.
First, I simply looked at the average sentiment, numerically, using the AFINN dictionary. This dictionary assigns a discrete numeric category to words (from -5 to 5) based on their sentiment. To do a quick check, I ran some code checking the average sentiment by whether a post was quarantined or not. Amazingly, there was a significant difference. On average, non-quarantined posts had a tendency to be positive, while quarantined posts had a tendency to be negative. They both floated around the neutral rate, with the respective average ratings being between -1 and 1.
Partially, this has to do with the low identification rate. The dictionary for AFINN, and the NRC dictionary used later, only had a few thousand unique words which they categorized. The natural english lexicon is much larger, and even larger are the several foreign language communities that have found a home on Reddit. This led to around 70% of the words in titles not being identified as having any sentiment.
After seeing the significant difference in post sentiment, however, I was curious whether there were any insights to glean if I broke the language into categories, and it turned out there really were.
After merging the NRC dictionary onto the posts dataset, I decided to graph the post breakdown by category that the words fell into. It turns out that several of these posts in the quarantined subreddits are drastically different in lingual composition than their non-quarantined counterparts. Quarantined posts are overwhelmingly more negative, and more angry. They’re definitely less trusting. Non-quarantined posts are largely happier and anticipatory.
What else?
Thanks to the incredible support and mentorship I received in this project during my time at the Federal Reserve, this has become part of an ongoing research project. I’m being challenged far more computationally than I would have expected even three years ago, but doing work that could expand applied micro methodology has been quite interesting.
Currently, I’m examining how to build custom sentiment lexicons for slang words used in online social networks. Doing this has required the usage of word2vec and other NLP methods to build a matrix of word distances between slang words and words already identified in sentiment dictionaries. From here, I’ll be testing the significance in differences between community sentiments of politically-charged words (e.g. ‘woman,’ ‘muslim,’ etc.).
I have also been manipulating the dataset to map interaction networks between already radicalized individuals and individuals who haven’t begun regularly participating in ‘radical’ networks. By building a network of linkages using comment chains, I’ll be able to track information spillover. More blog posts to come!
There’s more I’d like to look into. I’m curious if there’s a way to map community turnover to the likelihood of a specific subreddit being quarantined. What leads to this sort of pervasive negativity? Whose fault is it? Or, as conventional wisdom has asserted, the echo chamber has led to individuals radicalizing each other?
Many quarantined subreddits have political undertones. Some, like /r/incels (now /r/braincels) decry feminism and have often been cited as inspiration in radicalized shootings and attacks on individuals around the world. Others, like those supporting President Donald Trump, have also played a part in radicalization across the country, though it’s unclear how much credit can be given to these online forums. The novel implications of this dataset are that it is one of the first datasets where community radicalization almost solely happens on a public forum, written explicitly. There is some power in having this data available for analysis, if one has the computational abilities to do it.